파이써닉 코드, pythonic code란 파이썬 스타일의 코드를 말한다. 파이썬 스타일의 코드라는건 무엇인가 말그대로 파이썬스럽다는 의미이다. 파이썬 느낌이 나는 세련된 코드? 라고 할 수도 있겠다. 파이썬 특유의 문법을 활용해서 잘 만든 센스있는 코드.
why pythonic code?
옛날 프로그래밍 언어들은 컴퓨터의 연산속도를 고려하여 수행능력을 높이는데 초점을 두었다. 하지만 지금은 컴퓨팅 능력이 기하급수적으로 발달해서 현재의 프로그래밍에서는 개발자의 편의성이 더 중요해졌다. 코딩하는 사람이 편하게 효율적으로 일해야 더 좋은 결과물이 나오니깐.
그러한 관점에서 파이썬이 유용한 프로그래밍 툴이라 대세가 된 것이고 따라서 그런 파이썬의 장점을 십분 활용하는 것이 코딩을 잘하는 방법이다.
그밖에 pythonic code를 사용하는 이유들
- 복잡하고 고급스러운 코드를 작성해야 할 수록 파이써닉 코드가 더욱 필요해진다.
- 다른 사람이 짜놓은 코드를 이해하기 위해서 필요하다. (대부분의 개발자들이 파이썬 스타일로 코드를 짜기 때문에)
- 더 빠르고 효율적인 코딩을 작성할 수 있다.
- 보기에도 간결해보이고 있어보인다 (간지난다)
기본적인 pythonic code 종류들
- Split & Join
- List Comprehension
- Enumerate & Zip
- Map & Reduce
- Asterisk
join
리스트의 원소들을 합쳐서 하나의 문자열로 만드는 작업을 한다고 해보자.
a = ['KOREA','JAPAN','CHINA']
result = ''
for i in a:
result += i
result
'KOREAJAPANCHINA' ##결과기본적인 for 반복문을 써서 만들면 위와 같이 될 것이다.
이것을 pythonic code로 만들면
a = ['KOREA','JAPAN','CHINA']
result = ''.join(a)
result
'KOREAJAPANCHINA' ##결과이렇게 join 함수를 써서 한줄로 간단히 만들 수 있다. result를 빈칸으로 정의함과 동시에 a에 있는걸 join해서 넣으라는 명령까지 함께 전달하는 것이다. 이런 식으로 만드는 것을 pythonic code라고 한다.
a = ['KOREA','JAPAN','CHINA']
'-'.join(a)
'KOREA-JAPAN-CHINA' ##결과join을호 합칠 때 이렇게 연결부호를 입력해서 붙일수도 있다.
split
join과 반대로 문자열을 분리하는 함수이다. 예를 들면 노래가사나 연설문 같은 텍스트 안에 특정 단어가 몇 번 언급되었는지를 계산한다던지 할 때 먼저 텍스트 덩어리를 각 단어로 분리해야 할 것이다.
test="korean,english,japanese,chinese"
test.split(",")
['korean', 'english', 'japanese', 'chinese'] ##결과설명이 필요없을 정도로 사용방법이 간단하다. 변수명.split(“구분자”) 형태로 입력하면 나눠서 각각을 원소로 하는 리스트 형태로 반환해준다.
test="korean,english,japanese,chinese"
a,b,c,d=test.split(",")
print(a,b,c,d)
korean english japanese chinese ##결과split으로 나누면서 변수명을 할당해서 나눈 원소들이 각각의 새로운 변수로 할당되도록 해줄수도 있다.
list comprehension
다음은 리스트를 파이썬 스타일로 만드는 방법이다. pythonic code 중에서 가장 중요한 부분이라고 할 수 있다.
1부터 10까지의 숫자를 원소로 하는 리스트를 만든다고 하자.
result = []
for i in range(1,11):
result.append(i)
result
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10] ##결과이렇게 range로 돌릴 숫자 범위를 지정해주고, for loop 반복문으로 숫자 하나씩 result 리스트 변수에 append 되도록 하면 된다. append는 리스트 공부할때 봤던 새로운 원소를 리스트의 마지막에 추가시키는 함수이다.
이것을 list comprehension 파이썬 스타일 코드로 만들면 어떻게 바꿀 수 있을까.
result = [i for i in range(1,11)]
result
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10] ##결과이렇게 for문을 리스트 안에 넣어버리면 리스트 원소가 이런 것이다 하고 바로 지정해버릴 수 있다. 이것이 파이썬 스타일 코딩인 list comprehension이다.
nested loop
word1 = "Hello"
word2 = "World"
print([i + j for i in word1 for j in word2])
## 결과
['HW', 'Ho', 'Hr', 'Hl', 'Hd', 'eW', 'eo', 'er', 'el', 'ed', 'lW', 'lo', 'lr', 'll', 'ld', 'lW', 'lo', 'lr', 'll', 'ld', 'oW', 'oo', 'or', 'ol', 'od'] for문을 두개 결합하여 위와 같이 만들수도 있다. 리스트 [ ] 안에 원소는 i+j가 되는데
for i in word1
for j in word2
이중 반복문 구조로 먼저 i가 word1에서 하나 할당된 후 그 때 word2에서 j를 하나씩 가져오면서 한번 싹 매칭시키고 word1의 다음 i에 대해 또 j 를 한번씩 반복하는 식이다.
알아보기 쉽게 원래의 for 반복문 구조로 풀어서 쓰면 아래와 같다.
word1 = "Hello"
word2 = "World"
result=[]
for i in word1:
for j in word2:
result.append(i+j)
print(result)
## 결과
['HW', 'Ho', 'Hr', 'Hl', 'Hd', 'eW', 'eo', 'er', 'el', 'ed', 'lW', 'lo', 'lr', 'll', 'ld', 'lW', 'lo', 'lr', 'll', 'ld', 'oW', 'oo', 'or', 'ol', 'od']for문이 하나 있고 하부구조에서 하나가 더 돌아가는 셈이다. 이것은 일전에 for 반복문 공부할때 봤던 중첩루프 nested loop 구조이다. 생각이 안나면 파이썬 반복문 글을 복습
리스트 조건추가
또한 리스트 형성시 if 조건문을 같이 넣어서 필터링 기능도 추가해줄 수 있다.
case1 = ["A","B","C"]
case2 = ["D","E","B"]
result = [i + j for i in case1 for j in case2 if not(i=="B")]
result
##결과
['AD', 'AE', 'AB', 'CD', 'CE', 'CB']이렇게 뒤에다 if를 붙여서 특정 조건일 때, 또는 뭐는 빼고 등등 필터링을 해줄 수 있다. 위에서는 case1에서 B를 포함하지 않도록 해주었고 그래서 결과를 보면 앞자리가 A랑 C만 있는것을 볼 수 있다.
2 dimensional list
2차원 리스트도 파이써닉 코드를 이용해서 생성할 수 있다. 2차원 리스트도 예전에 리스트 학습때 봤던 개념이니 기본적인 내용은 아래 링크를 참조
어떤 문자열 원소들로 구성된 리스트가 있을 때 각 단어를 대문자,소문자,글자수로 표시하는 리스트를 만들어보자.
country = ["Korea","Japan","China"]
result = [ [i.upper(), i.lower(), len(i)] for i in country ]
result
## 결과
[['KOREA', 'korea', 5], ['JAPAN', 'japan', 5], ['CHINA', 'china', 5]]이렇게 [대문자,소문자,글자수]로 표시하는 리스트를 하나 지정하고 그 리스트의 i 자체가 country 에서 하나씩 불러오면서 for반복문을 돌도록 하면 country 원소 개수만큼의 하부 리스트를 가지는 이차원 리스트가 형성된다.
1차원 리스트와 2차원 리스트의 차이
case1 = ["A","B","C"]
case2 = ["D","E","B"]
result1 = [ i + j for i in case1 for j in case2 ]
print(result1)
result2 = [ [ i + j for i in case1 ] for j in case2 ]
print(result2)
## 결과
['AD', 'AE', 'AB', 'BD', 'BE', 'BB', 'CD', 'CE', 'CB']
[['AD', 'BD', 'CD'], ['AE', 'BE', 'CE'], ['AB', 'BB', 'CB']]위에서 만든 nested loop 리스트를 2차원 리스트가 되도록 괄호를 추가해주었다. result2를 보면 case2의 j가 먼저 하나 할당되고 하부 리스트인 i+j를 수행하게 된다. 즉 여기서는 case2 j에 대해 case1의 i를 각각 매칭시켜서 하나의 리스트로 만들고 다시 다음 j에 대해 하위 리스트를 만드는 식이다.
Enumerate
리스트에서 원소 (Element) 값을 추출할 때 인덱스 번호를 매겨서 뽑아준다. 바로 예제를 통해 익혀본다.
기본적인 사용법
for i, v in enumerate(["A","B","C"]):
print (i,v)
## 결과
0 A
1 B
2 C기본적으로는 이렇게 사용한다. enumerate(어떤 리스트) 형태로 입력하면 0,첫번째 원소 1,두번째 원소 2,세번째 원소 식으로 값을 추출해 준다.
list(enumerate("ABCD"))
## 결과
[(0, 'A'), (1, 'B'), (2, 'C'), (3, 'D')]그냥 enuemrate(값) 으로만 입력하면 <enumerate at 0x20808056140> 이런 형태로 값을 주기 때문에 어떤 식으로 출력할지 리스트같은 형태로 지정을 해주어야 한다.
사전형태로 만들기
a="ABCD"
{i : v for i , v in enumerate(a)}
## 결과
{0: 'A', 1: 'B', 2: 'C', 3: 'D'}이렇게 사전 (dictionary) 형태로 지정해서 인덱스 번호와 원소값이 key:value 쌍이 되도록 지정해 줄 수도 있다. 딕셔너리 사전자료형에 대한 내용도 복습해보자.
단어 스플릿과 응용
text="Pectus excavatum, also referred to as “sunken chest,” is a depression in the chest wall."
{i : v.lower() for i, v in enumerate(text.split())}
## 결과
{0: 'pectus',
1: 'excavatum,',
2: 'also',
3: 'referred',
4: 'to',
5: 'as',
6: '“sunken',
7: 'chest,”',
8: 'is',
9: 'a',
10: 'depression',
11: 'in',
12: 'the',
13: 'chest',
14: 'wall.'}split과 같이써서 이렇게 단어별로 만들어 줄 수도 있다. 위 명령어의 동작 순서를 풀어보면 아래와 같다.
1) 어떤 텍스트 단락을 문자형 변수로 지정해놓고,
2) 변수명.split 으로 단어별로 짤라준 뒤
3) 거기에 enumerate를 씌워서 인덱스 번호와 원소 쌍으로 값을 추출
4) 그것을 key:value 쌍의 사전 형태로 저장하여 출력
zip
두 개 이상의 리스트에서 같은 인덱스 번호에 있는 원소 (element) 값들을 병렬적으로 묶어서 추출해주는 기능이다.
기본적인 사용법
a = ["a1","b1","c1"]
b = ["a2","b2","c2"]
for a,b in zip(a,b):
print(a,b)
## 결과
a1 a2
b1 b2
c1 c2이렇게 zip(변수1, 변수2) 형태로 지정하면 각 리스트형 변수들에서 같은 인덱스 위치에 있는 원소들끼리 묶어서 추출해준다.
만약 b 리스트에는 c2가 없어서 원소 개수가 하나 적다면? 그러면 같은 인덱스 번호의 원소를 뽑을 수 있는 b2 까지만 동작을 수행한다.
2차원 리스트 컴프리헨션
a = ["a1","b1","c1"]
b = ["a2","b2","c2"]
[[a,b] for a,b in zip(a,b)]
## 결과
[['a1', 'a2'], ['b1', 'b2'], ['c1', 'c2']]일반적으로는 이렇게 2차원 리스트 (2 dimensional list) 형태로 분류해서 데이터를 정리한다.
응용
math = [100, 90, 80]
eng = [85, 78, 92]
history = [90, 69, 88]
[sum(score) / 3 for score in zip(math,eng,history)]
## 결 [91.66666666666667, 79.0, 86.66666666666667]
이렇게 각 과목별로 학생 번호순서대로 점수를 입력해놨다고 하자. zip을 이용해서 첫번째 학생의 각 과목 점수들만 불러올 수 있으므로 그것을 더하고 나눠서 평균 점수를 한번에 내주는 수식을 만들 수 있다. 파이썬 프로그래밍은 결국 배운 코드들을 직접, 많이 해서 익히고 그걸 센스있게 잘 응용해서 짜는게 실력인듯.
enumerate & zip
a = ["a1","b1","c1"]
b = ["a2","b2","c2"]
for i, values in enumerate(zip(a,b)):
print(i,values)
## 결과
0 ('a1', 'a2')
1 ('b1', 'b2')
2 ('c1', 'c2')마지막으로 enumerate 하고 zip을 같이 쓰는 방법이다. 먼저 zip으로 두 리스트의 같은 인덱스 원소들끼리 추출한 뒤 거기에 다시 enuemrate를 씌워서 인덱스 번호를 붙여준다. 그리고 i (인덱스 번호) values (원소값을 튜플 형태로 지정) 해서 출력을 해주었다.
values를 안쓰고 그냥 (a,b) 로 하던가 아니면 [a,b] 리스트 형태로 해주어도 상관없다. 원하는 자료형태로 만들어주면 된다.
파이써닉 코드 속도비교
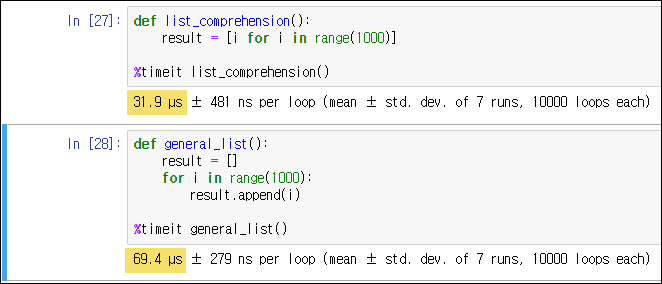
리스트 컴프리헨션과 반복문으로 형성시의 속도 비교를 해보면 pythonic code를 사용했을 때 절반 가까이 더 빠르게 동작하는 것을 알 수 있다.
처음에는 새로운 코드를 배우는 것 같아서 어려운 느낌이었는데, 막상 요 간단한 문장만 이해하면 pythonic code가 오히려 사람이 이해하기가 훨씬 쉽고 편리한 것을 알 수 있다. 파이썬이 좀 재밌어지기 시작하는 부분이다.
